


When the Dali masks was brought back to life in May 2017 by the Spanish heist crime drama television, La casa de papel, it felt like a watershed moment. The show went on to be one of the most popular shows on Netflix by virtue of the plot, its incredible actors but also because of the Dali mask. The mask became a symbol of the show. But why Dali and not Velasquez, Warhol or even Picasso? In my opinion, that’s the emblem of the wonderful craziness Dali had in his life. That must have been the thought process of the guys in OpenAI – a lab founded by Elon Musk that is also backed by Microsoft when they created a text-to-image generator. Dall-E is a portmanteau coined after combining the artist Salvador Dali and robot WALL-E from Pixar film of the same name. With the ability to generate a realistic image from the description of the scene or object, DALL-E combines the wonderful craziness of the surrealist artist with the making-life-easier attribute of the Disney robot.

DALL-E has two main components. An auto-encoder that learns to accurately represents images in a compressed latent space and a transformer which learns the correlations between languages and this discrete image representation. The auto encoder technique adopted by DALL-E to learn its discrete representations is called dVAE which is only slightly different from VQ-VAE (which stands for Vector Quantized Variational Auto encoder). I admit, that sounds complex, especially if you do not have some knowledge of Deep Learning or Machine Learning. An auto encoder is an unsupervised learning technique that uses neural network to find non-linear latent representation for a given data distribution. Hence, VQ-VAE is a type of variational auto encoder that uses vector quantization to obtain a discrete latent representation.
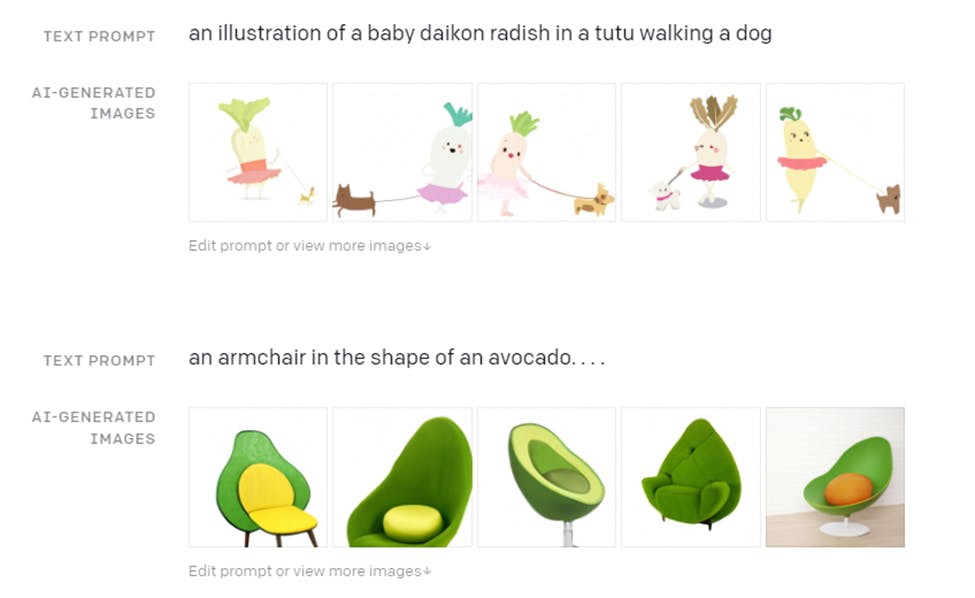
The transformer on the other hand, is arguably the meat of DALL-E. It is what allows the model to generate new images that accurately fit with a given text prompt. It learns how language and images fit together, so that when the model is asked to generate images of an ‘armchair in the shape of an avocado’ as shown above/below, it is able to spit out some creative designs for avocado chairs that have probably never been thought of before. Beyond just creative and accurate designs, the transformer also seems to understand some common sense physics. For instance, asking for the ‘illustration of a baby panda with headphones staring at its reflection in a mirror’ is seen to produce roughly the images above, all the way down to the physical details of the mirror’s reflection.
What you’re looking at is the end result of DALL-E. The program (its predecessor produced cartoony images) can craft high-res pics from text queries such as “cats playing chess” or “an astronaut riding a horse.” DALL-E turns words into visuals by combing through millions of images and their text captions to learn what’s in each photo—and then recreates and combines those elements to the limits of the human imagination.
In April 2022, OpenAI announced DALL-E 2 claiming that it can produce photo-realistic images from textual descriptions, along with an editor that allows simple modifications to the output. As of the announcement, the software was stated to still be in research phase, with access limited to pre-selected beta users. DALL-E 2 was described as a model that ‘can create original, realistic images and art from a text description. It can combine concepts, attributes, and style”. Furthermore, DALL-E 2’s art is strictly Bob Ross-approved. Obscenities, nudity, conspiracy theories, and actual likenesses aren’t allowed, which could help allay fears that DALL-E will be used to spread misinformation.
In conclusion, it is worthy of note that I did not go into all the mathematical details of the model and only touched on the key components to fulfill all righteousness because I would need to devote an entire blog post to that to really do them justice. Moreover, given that some knowledge of deep learning and Bayesian Probability would be a prerequisite to understand the intricacies and this blog post sticks to just the fundamentals for the AI-savvy and the non AI-savvy.