
Project 9 - Medical Insurance Cost Prediction using Machine Learning with Python
My Machine Learning Beginner Projects, Entry 9


I am Salim Olanrewaju Oyinlola. I identify as a Machine Learning and Artificial Intelligence enthusiast who is quite fond of making use of data and patterns to develop insights and analysis.
In my opinion, Machine learning is where the computational and algorithmic skills of data science meets the statistical thinking of data science. The result is a collection of approaches that requires effective theory as much as effective computation. There are a plethora of machine learning model, with each of them working best for different problems. As such, I believe understanding the problem setting in machine learning is essential to using these tools effectively. Now, the best way to UNDERSTAND different problem settings is by PLAYING AROUND with different problem settings. That is the genesis behind this writing series - My Machine Learning Projects. Over the course of this writing series, I would solve a machine learning problem daily. These problems will range from a plethora of fields whilst requiring and covering a range of models. A link to my previous articles can be found here.
Project Description: This project is a regression problem that predicts the medical insurance cost for citizens using certain attributes.
URL to Dataset: Download here
Line-by-line explanation of Code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
This block of codes above imports the third-party dependencies needed in the model.
import numpy as np imports the numpy library which can be used to perform a wide variety of mathematical operations on arrays.
import pandas as pd imports the pandas library which is used to analyze data.
import matplotlib.pyplot as plt imports the PyPlot function from the MatPlotLib library which is used to visualize data and trends in the data.
import seaborn as sns imports the seaborn library which is used for making statistical graphics. It builds on top of matplotlib and integrates closely with pandas data structures. Seaborn helps you explore and understand your data.
from sklearn.model_selection import train_test_split imports the train_test_split function from sklearn's model_selection library. It will be used in spliting arrays or matrices into random train and test subsets.
from sklearn.linear_model import LinearRegression imports the LinearRegression machine learning model.
from sklearn import metrics imports the metrics library from the sklearn library. This model is used to ascertain the performance of our model.
salim_insurance_dataset = pd.read_csv(r'C:\Users\OYINLOLA SALIM O\Downloads\insurance.csv')
This loads the data from csv file to a Pandas DataFrame.
salim_insurance_dataset.head()
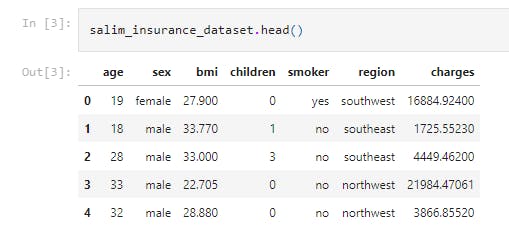
This prints out the first 5 rows of the dataframe.
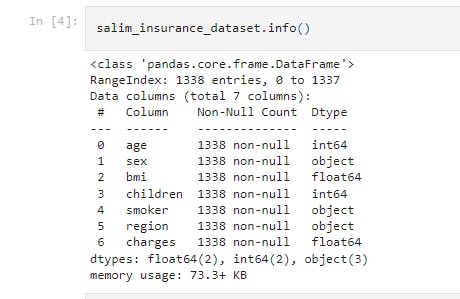
salim_insurance_dataset.info()
This gets some informations about the dataset.
salim_insurance_dataset.isnull().sum()
This checks for missing values.
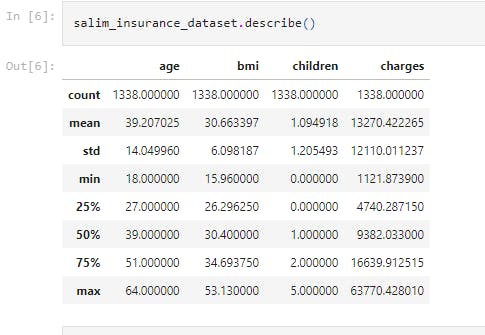
salim_insurance_dataset.describe()
This checks the statistical measures of the dataset.
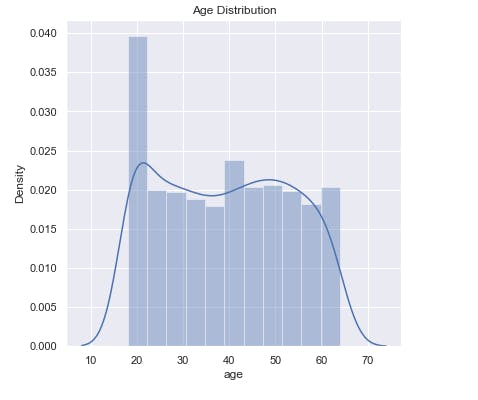
sns.set()
plt.figure(figsize=(6,6))
sns.distplot(salim_insurance_dataset['age'])
plt.title('Age Distribution')
plt.show()
This displays the distribution of age value.
plt.figure(figsize=(6,6))
sns.countplot(x='sex', data=salim_insurance_dataset)
plt.title('Sex Distribution')
plt.show()
This does the same for the Gender column.
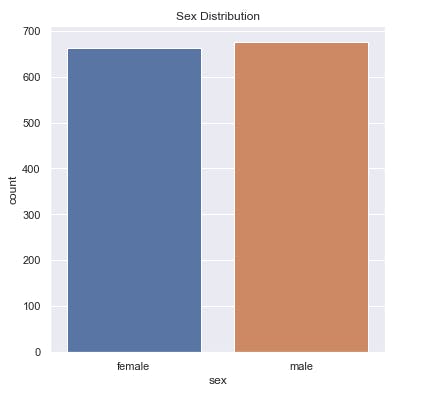
salim_insurance_dataset['sex'].value_counts()
This prints the number of males and females in the dataset.
male 676
female 662
plt.figure(figsize=(6,6))
sns.distplot(salim_insurance_dataset['bmi'])
plt.title('BMI Distribution')
plt.show()
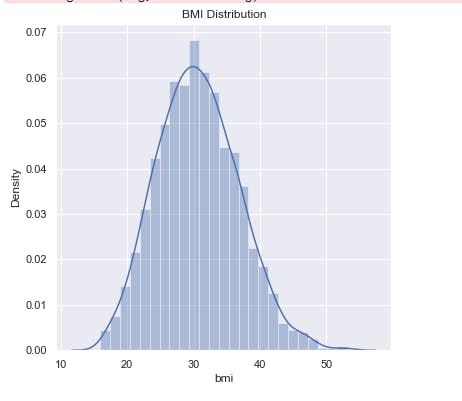
This displays the distribution of the bmi column.
- It is important to note that Normal BMI Range --> 18.5 to 24.9
plt.figure(figsize=(6,6))
sns.countplot(x='children', data=salim_insurance_dataset)
plt.title('Children')
plt.show()
This displays a countplot of the children column.
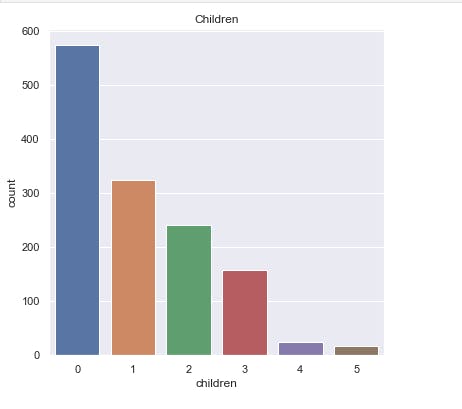
salim_insurance_dataset['children'].value_counts()
This displays the number of each unique values of the children column.
plt.figure(figsize=(6,6))
sns.countplot(x='smoker', data=salim_insurance_dataset)
plt.title('smoker')
plt.show()
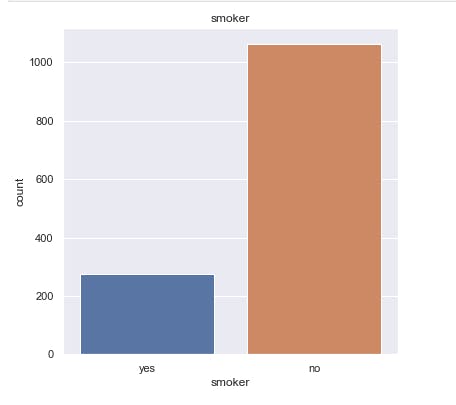
Evalauting the smoker column for better understanding.
salim_insurance_dataset['smoker'].value_counts()
This displays the number of each unique values of the smoker column.
plt.figure(figsize=(6,6))
sns.countplot(x='region', data=salim_insurance_dataset)
plt.title('region')
plt.show()
Evalauting the region column for better understanding.
salim_insurance_dataset['region'].value_counts()
This displays the number of each unique values of the region column.
plt.figure(figsize=(6,6))
sns.distplot(salim_insurance_dataset['charges'])
plt.title('Charges Distribution')
plt.show()
Evalauting the distribution for the charges column for better understanding.
The next step is label-encoding.
salim_insurance_dataset.replace({'sex':{'male':0,'female':1}}, inplace=True)
This encodes the sex column. As such, the male column represents 0 and the female column represents 1.
salim_insurance_dataset.replace({'smoker':{'yes':0,'no':1}}, inplace=True)
This encodes the smoker column. As such, the yes column represents 0 and the no column represents 1.
salim_insurance_dataset.replace({'region':{'southeast':0,'southwest':1,'northeast':2,'northwest':3}}, inplace=True)
This encodes the region column. As such, the southeast column represents 0, the southwest column represents 1, the northeast column represents 2, the northwest column represents 3.
X = salim_insurance_dataset.drop(columns='charges', axis=1)
Y = salim_insurance_dataset['charges']
This splits the Features and Target.
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=2)
The train_test_split method which was imported earlier is hence called and used to divide the dataset into train set and test set.
NOTE: The 0.2 value of test_size implies that 20% of the dataset is kept for testing whilst 80% is used to train the model.
regressor = LinearRegression()
regressor.fit(X_train, Y_train)
This creates an instance of the Linear Regression model and then, training it with the train dataset.
training_data_prediction =regressor.predict(X_train)
r2_train = metrics.r2_score(Y_train, training_data_prediction)
print('R squared vale : ', r2_train)
This predicts on the training set and evaluates the r2-score.
R squared vale : 0.751505643411174.
test_data_prediction =regressor.predict(X_test)
r2_test = metrics.r2_score(Y_test, test_data_prediction)
print('R squared vale : ', r2_test)
This predicts on the test set and evaluates the r2-score.
R squared vale : 0.7447273869684077.
input_data = (31,1,25.74,0,1,0)
# changing input_data to a numpy array
input_data_as_numpy_array = np.asarray(input_data)
# reshape the array
input_data_reshaped = input_data_as_numpy_array.reshape(1,-1)
prediction = regressor.predict(input_data_reshaped)
print(prediction)
print('The insurance cost is USD ', prediction[0])
At Step 1, we collect input data from the users.
At Step 2, we change input_data to a numpy array.
At Step 3, we reshape the array.
At Step 4, we do the prediction.
That's it for this project. Be sure to like, share and keep the discussion going in the comment section. .ipynb file containing the full code can be found here.